- Multimodal language-image instruction resource: LLaVA.pdf
Data Generation
- GPT-4: Used for generating instruction-following data
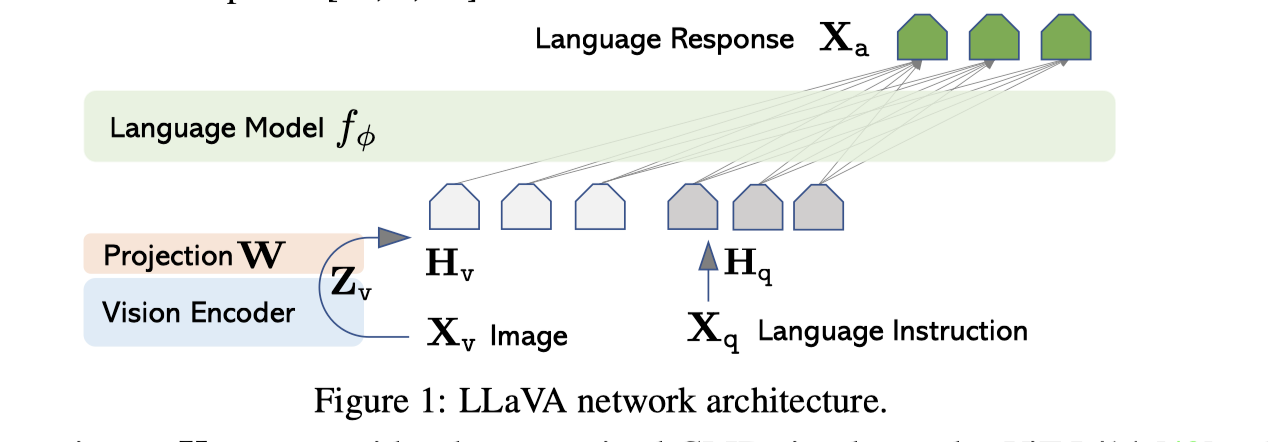
- CLIP (Vision Encoder): This is for [Visual instruction tuning]
- Vicuna (Language Model)
GPT-assisted Visual Instruction Data Generation
Visual instruction tuning