resource: https://pytorch.org/serve/large_model_inference.html
How it works
TorchServesets distributed environment- Uses round-robin to assign GPUs to a worker on a host
- in case of large inference, we can specify based on
model_config.yaml
- in case of large inference, we can specify based on
CUDA_VISIBLE_DEVICESis based on this number
ex:
For instance, suppose there are eight GPUs on a node and one worker needs 4 GPUs (ie, nproc-per-node=4) on a node. In this case, TorchServe would assign CUDA_VISIBLE_DEVICES=”0,1,2,3” to worker1 and CUDA_VISIBLE_DEVICES=”4,5,6,7” to worker2.
You can use Pippy integration
Pippy integration: Pipeline Parallelism for PyTorch

https://www.deepspeed.ai/tutorials/pipeline/
It partitions the layers of a model into stages that can be processed in parallel.

How Pipeline Parallelism Works
-
Model Segmentation: The entire neural network model is divided into several segments. Each segment can be seen as a subset of consecutive layers of the model.
-
Device Allocation: Each segment of the model is assigned to a different device. This way, multiple devices can be used to host the entire model, with each device responsible for computing the forward and backward passes of its assigned segment.
-
Mini-batch Splitting: The input data (mini-batch) is also split into smaller micro-batches. These micro-batches are then fed sequentially into the pipeline.
-
Sequential Processing of Micro-batches: The first micro-batch is fed into the first segment. Once the first device starts processing the first micro-batch, it can immediately pass its output to the second segment/device, and then start processing the second micro-batch. This process continues, creating a “pipeline” of operations across devices.
-
Parallel Computation: After the initial fill time (the time it takes to get all segments working on something), each device is continuously working on different micro-batches at different stages of processing (forward pass, backward pass). This parallelism increases the utilization of each device and speeds up the training process.
Challenges and Considerations
-
Communication Overhead: The need to pass data between devices can introduce communication overhead, especially if the devices are not closely interconnected.
-
Balancing Load: It’s crucial to divide the model into segments in a way that balances the computational load across all devices to avoid bottlenecks.
-
Bubble Time: There’s an inherent inefficiency called “bubble time” or “pipeline bubble,” which is the idle time when some devices are waiting for data to process. Optimizing the size of micro-batches and the number of segments can help minimize this effect.
gRPC Server Side Streaming
- gRPC Remote Procedure Call
- Uses HTTP 2.0, Protocol Buffers as the interface description language, and provides features such as authentication, load balancing, and more
Server-side Streaming RPC
What
- Client sends a single request to server and receives a stream of responses
How it works?
-
Client Call: The client initiates the RPC call by sending a single request to the server.
-
Stream Initialization: Upon receiving the request, the server starts processing and initializes a stream of responses.
-
Data Streaming: The server then sends multiple response messages back to the client over the established connection. These messages are sent as soon as they are ready, without waiting for all the responses to be generated. This is particularly useful for real-time data streaming or when the full set of responses is not immediately available.
-
Completion: Once all the response messages have been sent, the server signals the end of the stream to the client. The client then closes the connection.
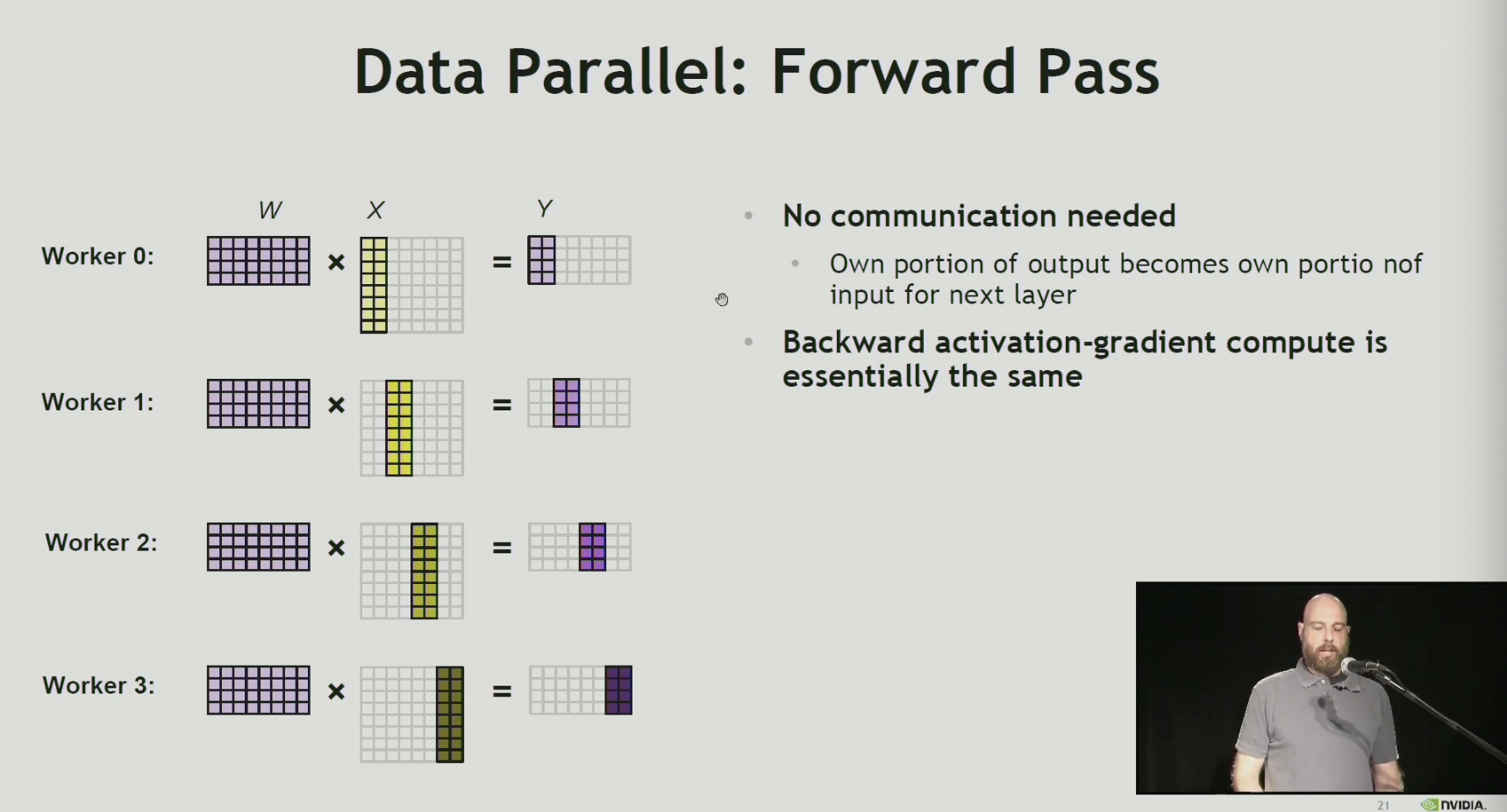
Large scale training
resource: https://www.youtube.com/watch?v=QzcbnI42-VI
Each worker:
- has a copy of the entire neural network model
- responsible for compute of a portion of data (training minibatch)
Communication
-
Allreduce
- any exposed co