Converting a model from using FP (like 32-bit floats) to using lower-precision formats (like 8-bit integers).
How does quantization work?
- Post-Training Static quantization: Entire model including weights and activations are converted to lower precision. Model is calibrated using a small calibration dataset to minimize the impact on accuracy. May not always have best accuracy.
- Dynamic Quantization: Weights quantized statically, but activations are quantized dynamocally at runtime. Method is often used for models wehre activation ranges can vary significantly depending on the input data.
- Quantization-Aware Training (QAT)
source: https://www.youtube.com/watch?v=0VdNflU08yA
Problem
- Smallest Llama 2 has 7 billion parameters. If every parameter is 32 bit, then we need just to store parameters on disk
- For inference, we need to load all its parameters in memory
How are integers represented in the CPU (or GPU)?

Python can represent arbitraty big numbers by using so BigNum arithmetic: each number is stored as an array of digits in base

How are floating point numbers represented?
Applying quantization
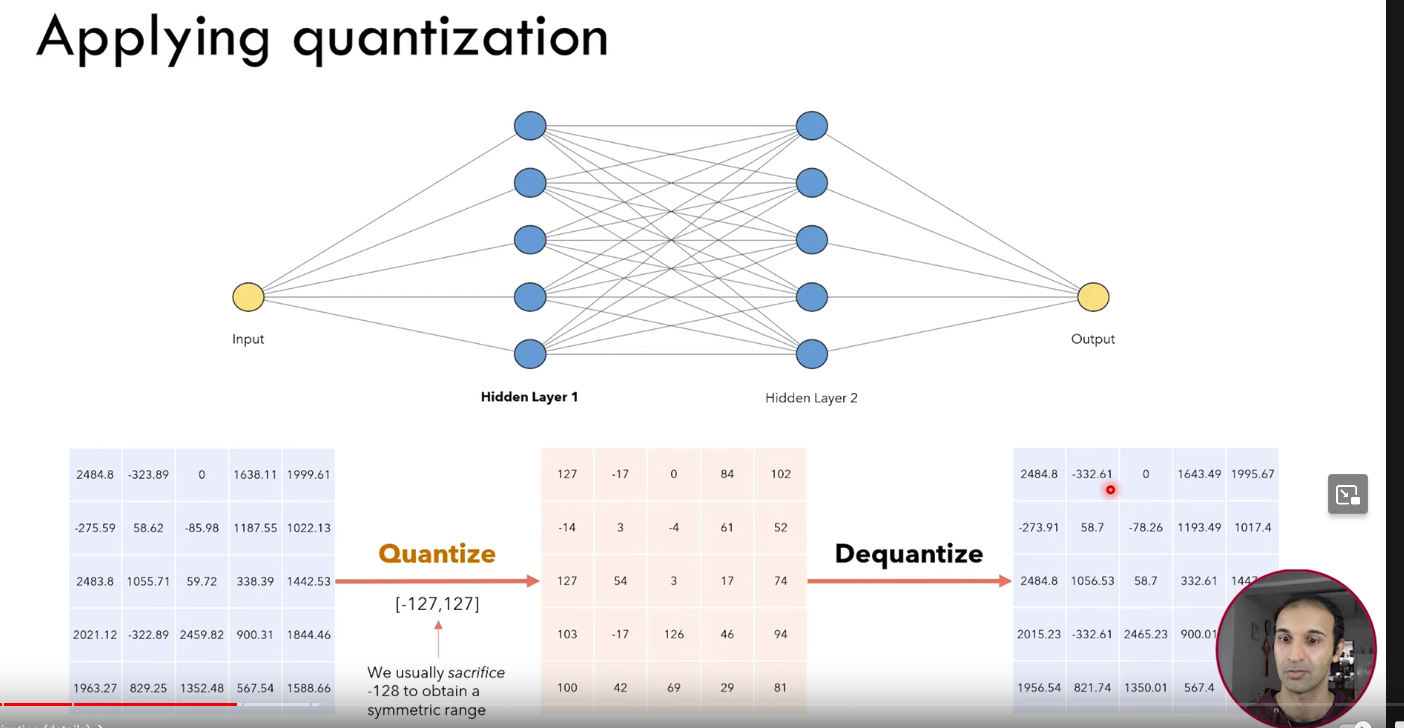
- Quantization first happens
- Then the integ arithmetic happens
- and then it’s deuqnatized and sent to the next layer
Types of qunatization
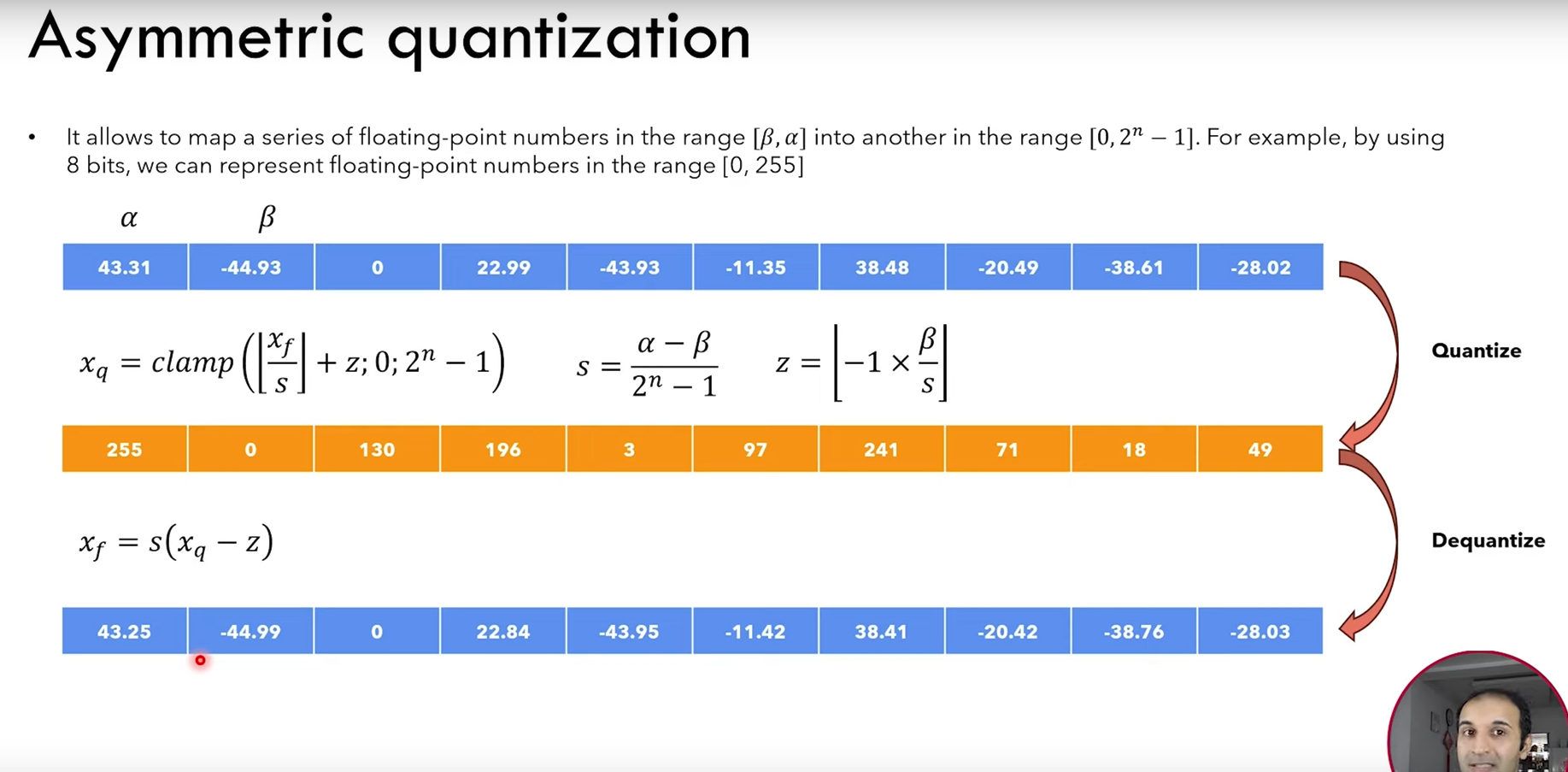
Assymetric vs Symmetric quantization

Low-precision matrix multiplication

How to choose range
Min-max:
- Sensitive to outliers
Percentile